Overview
Shows how Virtual Humans use a flexible set of backend solutions to demonstrate conversational behavior.
Leverages RIDE’s generic C# interfaces for Speech Recognition (ASR), Natural Language Processing (NLP), Text-To-Speech (TTS) and Non-verbal Behavior Generation (NVBG). Optionally includes sentiment analysis and entity analysis for NLP and Sensing (computer vision) with support for emotion and landmark recognition.
Initially supported services:
|
ASR
|
NLP
|
TTS
|
NVBG
|
Sensing
|
|
Windows Dictation Recognition (Native Windows service)
|
Azure QnA
|
AWS Polly Text To Speech and TTS Voice
|
NVBG System (External Windows Process)
|
Azure Face
|
|
Azure Speech Recognition (Google Speech SDK)
|
AWS Lex v1 & v2
|
Eleven Labs Text To Speech and TTS Voice
|
NVBG System (Local Integrated Class Library, Windows Only) |
AWS Rekognition
|
|
Mobile Speech Recognition (KKSpeech Recognizer Asset)
|
OpenAI
- GPT3
- Turbo GPT (3.5)
- GPT4
|
Windows TTS (External Windows Process) |
NVBG System (Remote RESTful Service) |
|
Supplemental Virtual Human Conversational Behavior:
- Gaze, Saccade
- Listening
- Emotion Mirroring
Review the Supported Services by Character and Platform section for which combinations of the above are currently expected to function.
Additionally, this scenario has the capability of utilizing custom user created backend implementations for any of the above systems. Requires knowledge of RIDE’s generic C# interfaces.
How to Use
Run the scene and use the sandbox menu to control the scenario parameters.
Environment Tab
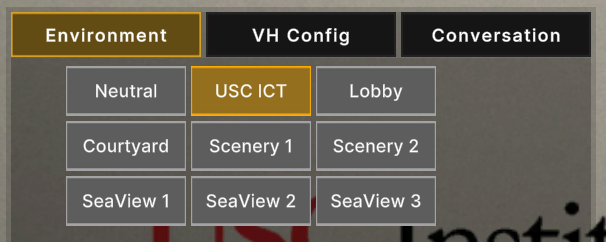
- Choose between six flat background images, including USC ICT logo, 3D lobby scene, and landscape photos.
- Three locations within the 3D SeaView environment.
VH Config Tab
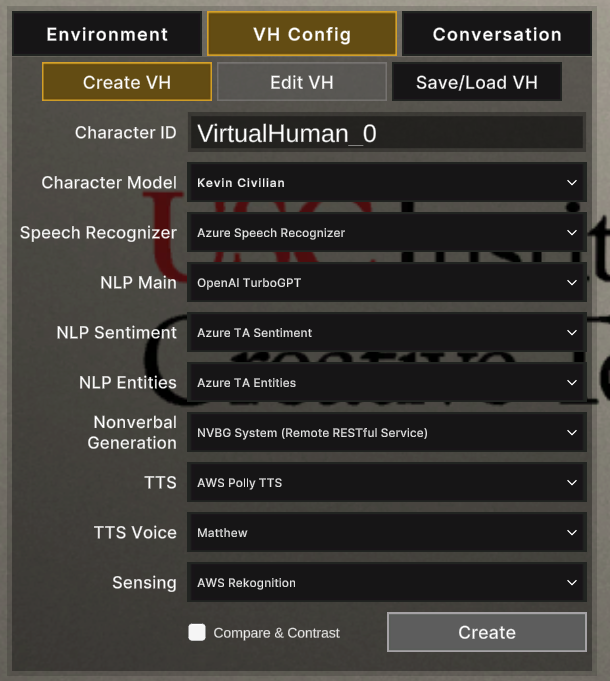
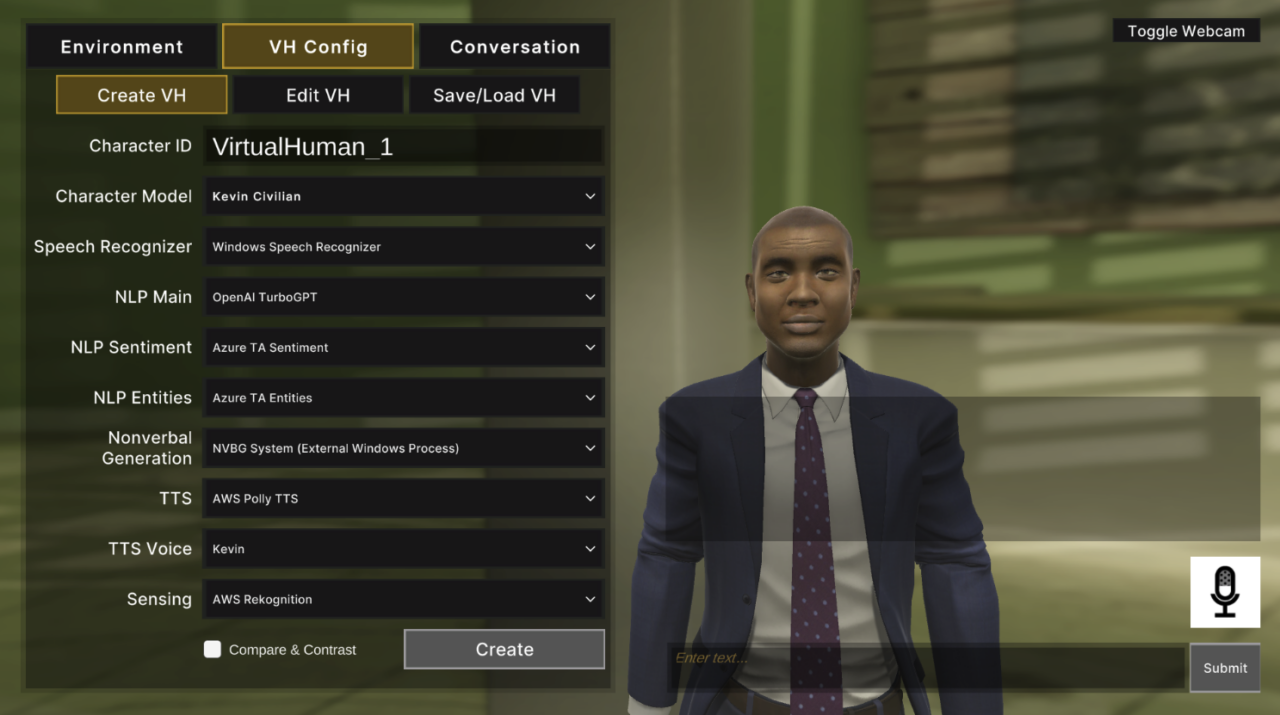
- Create VH: In this sub-tab, you can configure the backends you want to test before creating the Virtual Human by selecting the Create button.
- Character ID is prepopulated for each VH and is customizable; note, each VH must have a unique name.
- TTS Voice list is based on the selected TTS backend.
- Select Compare & Contrast to randomize the parameters prior to creation.
- Virtual Humans are created and placed within player FOV.
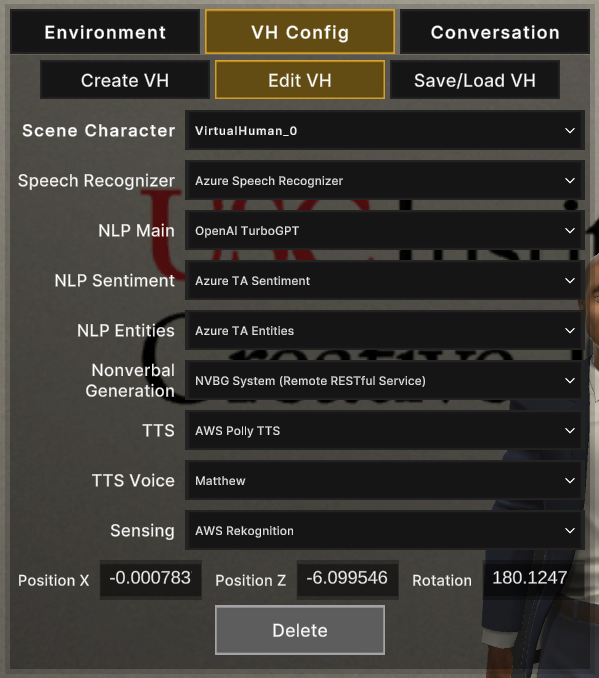
- Edit VH: In this sub-tab, you can swap the backends for already created Virtual Humans.
- VH model template cannot be modified after creation.
- VH position and rotation can be modified here.
- Select between instanced VH characters from the dropdown.
- Delete problematic or unwanted VH characters.
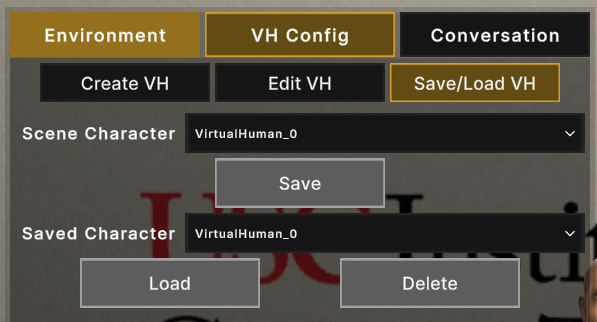
- Save/Load VH: In this sub-tab, you can save and load configured Virtual Humans to/from local storage.
- Saved VH configurations are identified by the VH name.
- VH configurations are saved as JSON. If in-scene backend objects have their name changed, the previously saved configuration will not load properly.
- If you load a VH configuration for an already created or loaded VH, the existing VH config will be overwritten by the loaded configuration.
Conversation Tab
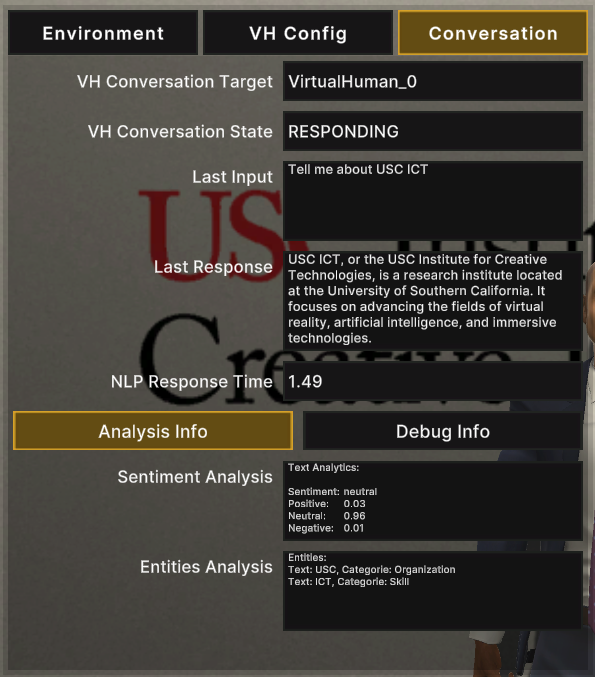
- This tab acts as conversation analysis/debugging.
- Tracks the current VH the user is having a conversation with.
- Has 2 sub-tabs, Analysis and Debug Info, for more in-depth information about the current conversation.
User Input
- Text Input: Use the designated input field and the Submit button to send a query to the current conversational VH.
- Audio Input: Press and hold the Push-To-Talk button and begin speaking.
- Input field will display detected partial speech (if supported by the current ASR backend).
- Query will be sent either once you release the push-to-talk button, or automatically if complete speech is detected, based on the current ASR system.
Toggle Webcam
- Turns on the webcam and begins sensing for the backend of the current conversational VH.
- Requires a created VH with an assigned Sensing backend.
- Webcam overlay displays the following information:
- Detected face rectangle
- Detected landmarks
- Detected head orientation
- Detected emotion
Key bindings:
|
Key
|
Action
|
|
F1
|
Toggle Sandbox Menu
|
|
V
|
Push-to-talk shortcut
|
|
J
|
Toggle mouse cursor control
|
|
F
|
Toggle webcam shortcut
|
|
Tab
|
Cycle Sandbox Menu tab
|
|
F2
|
Create Virtual Human shortcut
|
Scene Location & Name
Assets/Scenes/VHSandbox/VHSandbox.unity
Setup Requirements
The main script name and location: Assets/Scripts/VHSandboxExample.cs.
Below are the steps to add a custom VH backend implementation to the sandbox:
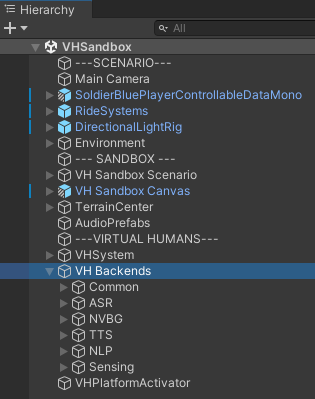
- Create your custom backend script, that implements one of the following Ride C# interfaces:
- ASR – ISpeechRecognitionSystem
- NLP – INLPQnASystem
- TTS – ILipsyncedTextToSpeechSystem
- NVBG – INonverbalGeneratorSystem
- Sensing – ISensingSystem
- Create a Unity gameobject with a user-friendly name and attach the created script.
- The Gameobject should be placed in the scene under the “VH Backends” object, and should not have the same name as another backend gameobject.
- To confirm the previous steps have been completed correctly, play the scene and see if the created gameobject name is displayed under the relevant backend dropdown.
Known Issues and Troubleshooting
Windows
Windows speech recognizer unavailable
- Ensure under Settings > Speech, Online speech recognition option is switched to On
Mac
App dependencies blocked from running by versions of macOS
Due to macOS security features, the OS may block certain dependencies at run-time. Use the following workaround for any prompts received:
- Open a terminal window at the IVA project folder
- Input the following to edit the file attributes: xattr -cr “Assets/Ride_Dependencies (local)/SpeechSDK/Plugins/MacOS/libMicrosoft.CognitiveServices.Speech.core.dylib”
- Input the following to edit the file attributes: xattr -cr “Assets/Ride_Dependencies (local)/Oculus/Oculus/LipSync/Plugins/MacOSX/OVRLipSync.bundle”
- Play the VHSandbox – Minimal scene again
Speech input and camera feed not available
- If prompted by the OS, enable access to your microphone and webcam
General
Config file out of date and errors when running any example scene
- Update the config file by launching LevelSelect > ExampleLLM scene
- Open the debug menu:
- Windows, press F11 key
- Mac, press (Command +) F11 key; note, may need to enable the option, System Preferences > Keyboard > “Use F1… as standard function keys”
- Config menu appears; if not, click header or arrow of debug menu
- Click Reset to Defaults button
- Return to LevelSelect and choose desired scene again
Services unavailable and various errors when running any example scene
- Ensure PC has an active Internet connection; majority of all services require Internet except for “local” or “external” Microsoft/Windows services
Example Scene
VHSandbox
- AWS Lex v1 selected as both NLP Main and NLP Sentiment will fail and soft-lock input section of UI; as workaround, create new VH, then delete the problematic VH
- Also occurs with NLP Main as AWS Lex v1 and NLP Sentiment as AWS Lex v2; as workaround, do not use AWS Lex as options in both fields
- Best practice if using AWS Lex, populate both fields with AWS Lex v2
- Character utterance audio may repeat and not match text for ElevenLabs voices
- Delay from click & hold until mic input status change to “listening”
- Mic input may fail to function with initial click & hold
- SeaView environment locations run very slow on lower-end hardware
- Rocketbox characters do not display face mirroring
- RenderPeople Test character does not display lipsync
- Mobile Speech Recognizer does not function on desktop systems
- Webcam view may fail to update with creation and/or deletion of multiple characters
- AWS Polly TTS, corresponding TTS Voice options may fail to populate
- Windows TTS (External Windows Process) may cause strong head nod at start of utterance for characters
- NLP Sentiment as AWS Lex v1 or v2 and TTS as ElevenLabs TTS causes VH unresponsiveness and soft-lock input section of UI
- Rocketbox characters with NLP Main set as AWS Lex v1 or v2 and TTS as ElevenLabs TTS may cause first utterance to repeat twice
- Binary only: NVBG System (Local Integrated Class Library, Windows Only) causes VH unresponsiveness and soft-lock input section of UI
Supported Services by Character and Platform
Note: * denotes a known issue.
| |
Character Model |
Platform |
| |
Rocketbox – Male |
|
|
| Kevin Civilian |
Rocketbox – Female |
|
Davis OCP
|
Rocketbox – Male_2
|
Render People Test |
Windows 10/11 |
MacOS |
| Speech Recognizer |
Windows Speech Recognizer |
|
|
|
Yes |
N/A |
| |
Azure Speech Recognizer |
N/A |
N/A |
N/A |
Yes |
Yes |
| |
Mobile Speech Recognizer |
N/A |
N/A |
N/A |
N/A |
N/A |
| NLP Main |
OpenAI TurboGPT |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Azure QnA |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
AWS Lex v1 |
Yes* |
Yes* |
Yes* |
Yes* |
Yes* |
| |
AWS Lex v2 |
Yes* |
Yes* |
Yes* |
Yes* |
Yes* |
| |
OpenAI GPT3 |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
OpenAI GPT4 |
Yes |
Yes |
Yes |
Yes |
Yes |
| NLP Sentiment |
Azure TA Sentiment |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
AWS Lex v1 |
Yes* |
Yes* |
Yes* |
Yes* |
Yes* |
| |
AWS Lex v2 |
Yes* |
Yes* |
Yes* |
Yes* |
Yes* |
| NLP Entities |
Azure TA Entities |
Yes |
Yes |
Yes |
Yes |
Yes |
| Nonverbal Generation |
NVBG System (External Windows Process) |
Yes |
Yes |
Yes |
Yes |
N/A |
| |
NVBG System (Local Integrated Class Library, Windows Only) |
No* |
No* |
No* |
No* |
N/A |
| |
NVBG System (Remote RESTful Service) |
Yes |
Yes |
Yes |
Yes |
Yes |
| TTS |
AWS Polly TTS |
Yes |
Yes |
Yes* |
Yes |
Yes |
| |
ElevenLabs TTS – Proxy |
Yes |
Yes |
Yes* |
Yes |
Yes |
| |
ElevenLabs TTS – Auto |
Yes |
Yes |
Yes* |
Yes |
Yes |
| |
ElevenLabs v2 TTS – Auto |
Yes |
Yes |
Yes* |
Yes |
Yes |
| |
Windows TTS (External Windows Process) |
Yes* |
Yes* |
Yes* |
Yes |
N/A |
| TTS Voice |
AWS – Kevin |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
AWS – Salli |
|
|
|
Yes |
Yes |
| |
Eleven Labs P – Rachel |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs P – Clyde |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs P – Arno |
|
|
|
Yes |
Yes |
| |
Eleven Labs P – Barack_Obama |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs A – Rachel |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs A – Clyde |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs A – Arno |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs A – Barack_Obama |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs v2 A – Rachel |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs v2 A – Clyde |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs v2 A – Arno |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Eleven Labs v2 A – Barack_Obama |
Yes |
Yes |
Yes |
Yes |
Yes |
| |
Microsoft – David |
Yes |
Yes |
Yes |
Yes |
N/A |
| |
Microsoft – Zira |
Yes |
Yes |
Yes |
Yes |
N/A |
| Sensing |
AWS Rekognition |
|
|
No*
|
Yes |
Yes |
| |
Azure Face |
Yes |
No* |
No* |
Yes |
Yes |